In order to provide a magical experience for our carsharing customers, Getaround vehicles are equipped with Connect® hardware that communicates with the Getaround network. That magic is powered by an entire IoT backend which we recently migrated. Some might call that magical. As our platform grew quickly, the initial infrastructure experienced stability issues and hindered our ability to scale or improve telemetry features. Migrating an internal service which powers the business is a bit tricky. A single mistake has the potential to shutdown business for hours if not days. With this in mind, we used an iterative and parallel approach to carefully migrate each feature from the old to the new.
We believe the best carsharing experience should be seamless– from booking, to finding and unlocking, and then returning the car. Getaround’s Connect® hardware powers this experience of finding and accessing the car and allows us to monitor our fleet’s health.
When Getaround started, IoT was still a relatively new field, and off-the-shelf services were limited at best. We created a proprietary telemetry backend and protocol. It was a single cloud server, running a service written in Erlang, receiving telemetry and routing commands and configurations to all vehicles on the platform.
At a high level our system looked like this.
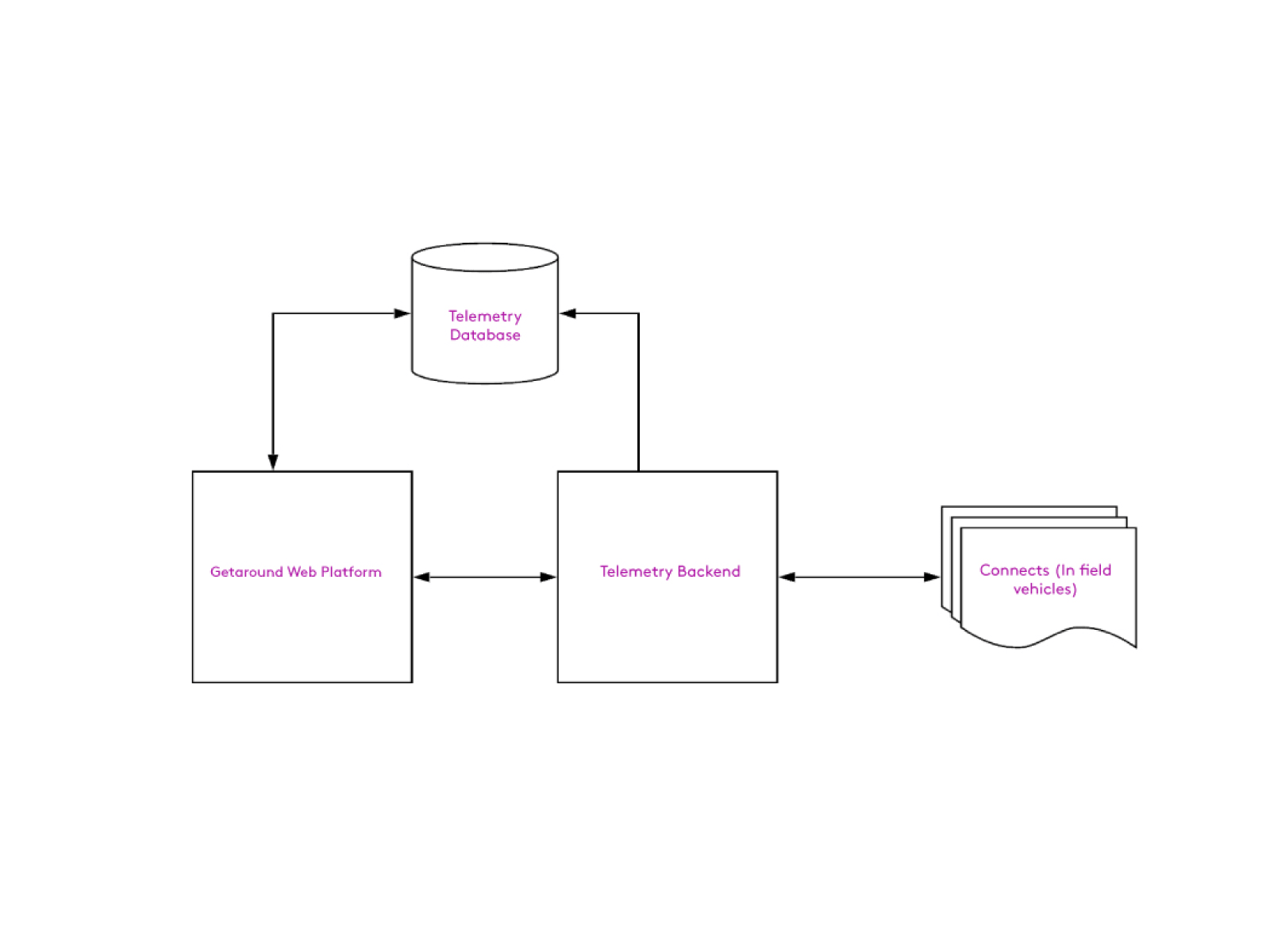
For years, with a smaller number of cars on our platform, this was functional and required minimal maintenance. However, once we started rapidly scaling, minor issues became huge problems:
IoT as a field had made leaps of progress in the years since we created our initial infrastructure. We decided the best way to scale our system was to switch away from our proprietary solution and use one of the newer off-the-shelf IoT products.
We began research and landed on four services to evaluate:
As we looked into these offerings we had a few metrics we were comparing:
First we eliminated ThingsBoard. Their software was interesting and open source, but it was geared towards running your own instance, like we had been. They had a SaaS offering as well, but we decided it was risky to use a relatively unknown and small company for a system which our entire business relied upon.
Next we eliminated Samsung Artik. Artik had similar issues as AWS in moving the data from Samsung to our platform in Google Cloud, but it was a much newer and less adopted system than AWS. Samsung Artik did offer COAP and MQTT, and we looked into it specifically to evaluate COAP, but we finally chose MQTT due to its more mature libraries and better TLS support. Samsung Artik had the same feature limitations as Google Cloud and the same integration problems of AWS.
Finally, the decision ended up being between Google and AWS. In evaluating the basic MQTT Telemetry (offering, cost, and limits), they both seemed similar. Since we had a working relationship with Google through our other backend systems, we decided it was beneficial to try and keep our services within Google Cloud Platform. The integration seemed simpler even though AWS was more established, flexible, and feature-rich.
Our first design thoughts were to replicate our current features falling largely into three categories:
As we began designing the commands and configuration infrastructure, we started to see the limits of Google’s Cloud IoT Core:
When sending a configuration request to a device, we wanted a system in which we could guarantee the configuration is sent whenever the device comes online, and monitored even while it is offline. We previously lacked this ability which hindered monitoring the state of any device. To do this with Google’s Cloud IoT Core, we would’ve had to implement another service with a database maintaining these configurations. As we started to design this system, it was almost as much work as implementing the entire IoT backend from scratch. We took a step back and started to rethink our decision regarding Google versus Amazon.
AWS IoT Core eventually won out because of the additional features offered along with the basic MQTT telemetry system:
As we looked deeper into Device Shadows, we realized the configuration system we were designing with Google Core IoT was a rudimentary version of AWS’ Device Shadows. Using AWS, we didn’t need to create supplementary services to achieve the functionality we desired. The only downside was that we needed an ETL from AWS to the rest of our company infrastructure in Google, but we decided the work to implement the ETL was far less than the work required to have Google Core IoT perform the way we needed. As much as we would’ve liked to have kept our systems contained within Google, their IoT product was too new and didn’t offer as many features as AWS.
When we designed the migration process we took into account how we release new Connect® features. When we develop a new feature for the Connect®, it is difficult to test all the real world situations the Connect® devices are exposed to. To verify these features, we roll out firmware releases iteratively to an increasing percentage of the fleet, and with feature flags on all the new features. Feature flags allow code to be exercised with the end result mocked out, making it possible to test new features in parallel with a functioning system.
During the migration, our system looked like this:
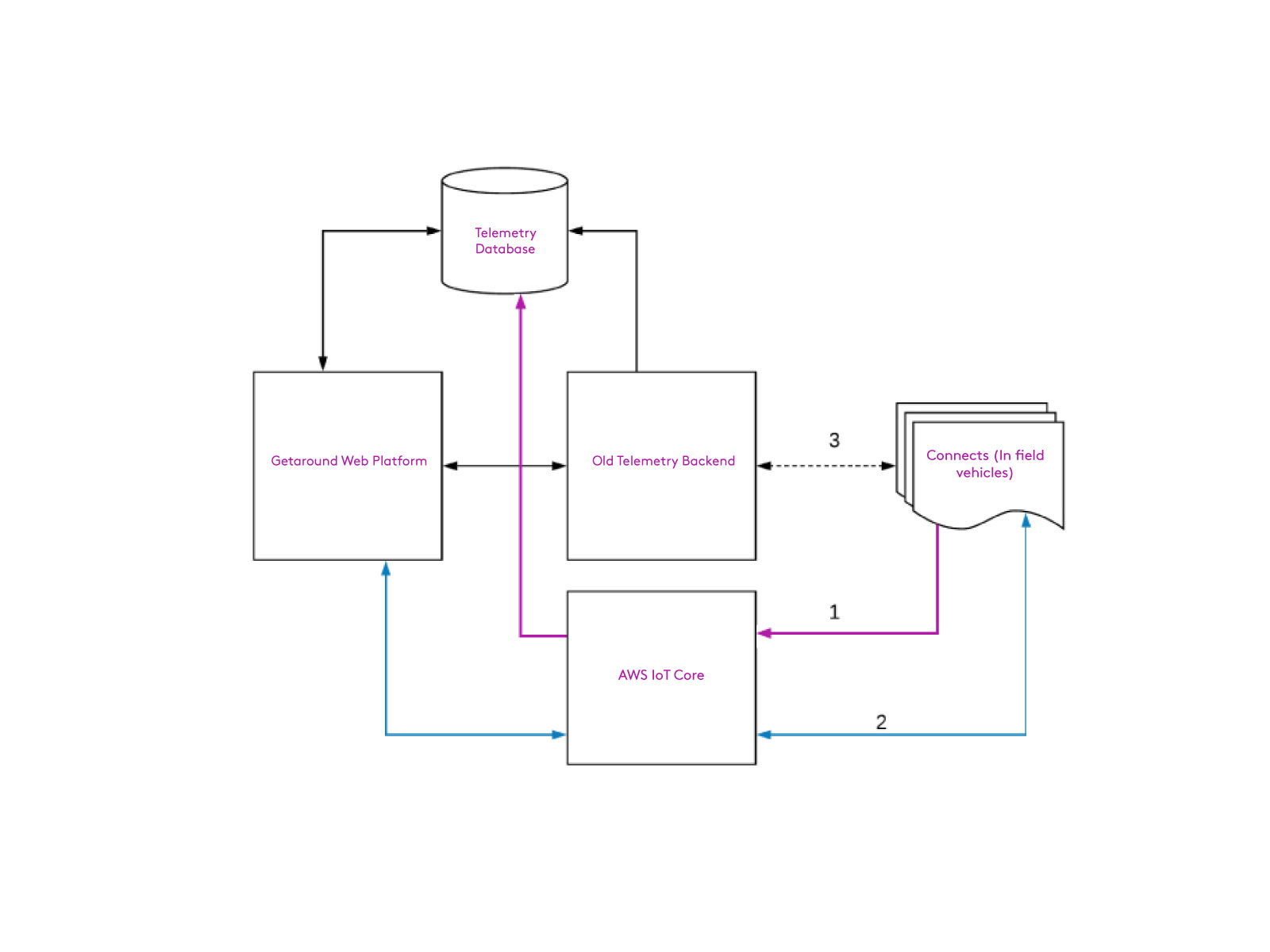
The first migration we implemented was our main telemetry feed from each vehicle. We rolled this out iteratively based on a flag that maintained the connection to the old backend, but when enabled, sent the data to AWS instead.
Ideally, we would have duplicated this data and sent it through both backends to our database for comparison, but the format of our database made this a complex task. Instead, after the firmware was released, we closely observed about 10 vehicles which had been switched over to AWS. Each of these vehicles could immediately revert back to the original network if required, and could also be accessed via SMS in an emergency. Once we identified and fixed some minor issues with these vehicles, we slowly (over the course of a month) increased the number of cars until all capable devices were sending telemetry through AWS.
We focused on commands once our telemetry was stable and fully released. Fortunately, commands did not have the same database complexity as our telemetry system, so we could run both AWS and legacy commands in parallel.
We implemented a feature flag which allowed AWS commands to function normally up until the point a Connect® executed a command (e.g. lock, unlock, set configuration). At this point, the device replied to AWS with a message saying it would’ve performed the action if the feature flag was enabled. This allowed us to test the the communication with AWS without unintentional consequences from any bugs in our implementation.
Using this feature flag and the same iterative rollout process, we were able to fully update the fleet and monitor the health of AWS commands while still using our older backend to do the actual work. This allowed us to verify that AWS commands were working as expected, and to roll out any bug fixes before actually using the feature. When our analytics confirmed that AWS commands were performing as well as before (it was actually better), we started another iterative rollout to flip the feature flag which actually acted on the AWS command. We still kept the previous commands enabled, but had deduplication logic in the Connect® to ensure we didn’t execute the command twice.
Finally, once we had sufficiently verified all commands running in parallel, we stopped sending commands through the old system if a device was registered with AWS, completing the migration of commands and no longer relying on the old infrastructure.
Now that our AWS implementation had reached feature parity, we had the option to disable the connection from the Connect® to our old server and complete the migration. Because of a number of legacy devices in our fleet, we still run the old system to ensure those vehicles are still operational, but the load is so minimal it takes virtually no effort.
The complete migration of our telemetry system, from choosing a new service to full migration, took just under a year. Each step had to be carefully considered to avoid any negative impact on our users. The migration would’ve been nearly impossible if it were not iterative and done in parallel with our older system. Every release was verified before roll out and we assured our operations teams that there would be no changes in day-to-day business during migration. Everything had to work the exact same way it always had.
There were a few hiccups along the way, but because we had iteratively rolled out all of our features in parallel with our old system, it was simple to revert back when we encountered issues. And with the iterative release, any issues we did encounter were confined to small portions of the fleet. Fixing a couple mistakes by hand is feasible, but a bug affecting the entire fleet would have been disastrous.
As a result, we finally have a fully scalable, distributed and flexible backend which no longer is the blocker in expanding the functionality of the Connect®. Now we just have to explore how to use all this new data!