This article is aimed at beginner Rubyists who want to understand what the fuss around type checking is all about. It can also be relevant for more experienced developers who might be interested in using Sorbet and learning why it’s a bit special.
First I need to say that Sorbet has not been released yet (a preview version is available). Stripe is improving it internally and some other companies are testing it. We can still talk about it because it should be open-sourced in the coming future (they said summer 2019) and it’s nonetheless very interesting. This blogpost is the result of watching talks, and reading articles, Twitter feeds and the official website. It may contain some small mistakes and some parts may be obsolete when Sorbet will be released.
To understand Sorbet we first need to understand what a type is. A type is a definition applied to a part of our program (this part can be a variable or a function for example). This definition usually says something like “this variable is a String” or “this function returns an Integer”. A type checker will enforce these definitions by raising an expection if it finds an incoherence. An incoherence can be something like “this variable is of type String and you try to call the method #map on it but this method does not exist on type String so this is incoherent”, and then it will raise an exception. This exception can be raised at runtime when the program is launched (this is called dynamic typing) or just by analysing the source code without executing it (this is called static typing). The tool that will enforce these types is called a type checker.
There are a lot of different type checkers and it’s a large research field. We don’t need to understand Type Theory (one of the mathematical theories used by type checkers) to enjoy their use. I will just focus on Sorbet and describe what you can do with it.
Sorbet is both a static and a dynamic type checker. It will catch wrong definitions as early as possible by analysing the source code (you should run it in your editor and/or before releasing your code). This is particularly useful because Sorbet is fast, it can analyze 100kloc/sec (Rubocop is around 1kloc/s for comparison), so it will find bugs instantly before you even launch your tests.
The more interesting and specific side of Sorbet is that it will run side by side with your Ruby code, verifying types at runtime. Sorbet’s creator decided to implement this because Ruby is a very dynamic language and a lot of Rubyists write code that will generate code.1 Plus, Sorbet is a gradual type checker.
A gradual type checker is a special kind of type checker because you don’t need to add type annotations to all your code to use it. You can start small, just use it in some parts of your code then extend its usage gradually when you feel the need. Actually Stripe even added a tool to Sorbet to find which parts of your code you should type check to have the most impact. You may think that these runtime checks are costly, but it does not seem like it 2, and you can be sure that since Stripe is using it in production, performance problems are taken very seriously.
First some typing.
# typed: true
extend T::Sig
sig do
params(time: Time)
.returns(String)
end
def format_time(time)
label = "Time is : "
formatted_time = time.strftime("%M:%H")
label + formatted_time
endAs you can see, Sorbet is just plain Ruby. First you add a # typed: true comment to instruct Sorbet that it’s a typed file (there are other values than true for different levels of strictness). Then you extend the object where you want to use it. Finally, you can call sig (short for signature) to define which types are your params and what the type of your returned value would be. This signature is applied to the definition of the next method.
sig takes a block as a parameter and in this block you use params that you chain with returns. These params and returns methods are the core of Sorbet.
Here I defined the params of my method format_time to be a Time and the return type to be a String. As you can see I didn’t have to type label because Sorbet can infer types and this makes it way more practical and less verbose than some other type Systems.
In the next bit of code we have an ActiveRecord-like Model with a .find and a #plate_number. This example simulates a common use-case where you query a record and ask for one of its attributes.
# typed: true
class Car
extend T::Sig
sig do
params(attributes: {id: Integer, plate_number: String})
.void
end
def initialize(attributes)
@attributes = attributes
end
sig do
params(id: Integer)
.returns(T.nilable(Car))
end
def self.find(id)
# We are simulating some kind of Database Query
if id == 1
new({
id: 1,
plate_number: "1234"
})
end
end
sig { returns(String) }
def plate_number
@attributes[:plate_number]
end
end
car = Car.find(1)
car.plate_numberResult:
editor.rb:35: Method plate_number does not exist on NilClass component of T.nilable(Car)
35 |car.plate_number
^^^^^^^^^^^^^^^^
Autocorrect: Use `-a` to autocorrect
editor.rb:35: Replace with T.must(car)
35 |car.plate_number
^^^
Errors: 1When we type check it with Sorbet , it warns us that we didn’t handle the case where we don’t find a Car. The message is pretty clear and it even recommends that we use a special method T.must. This will enforce at runtime that we always have a Car. This may not be what we want and we can handle the case ourselves by adding something like:
car = Car.find(1)
if car
car.plate_number
else
"A plate number's placeholder"
endAnd now Sorbet is happy. It understands the if ... else and there is no more risk of errors.
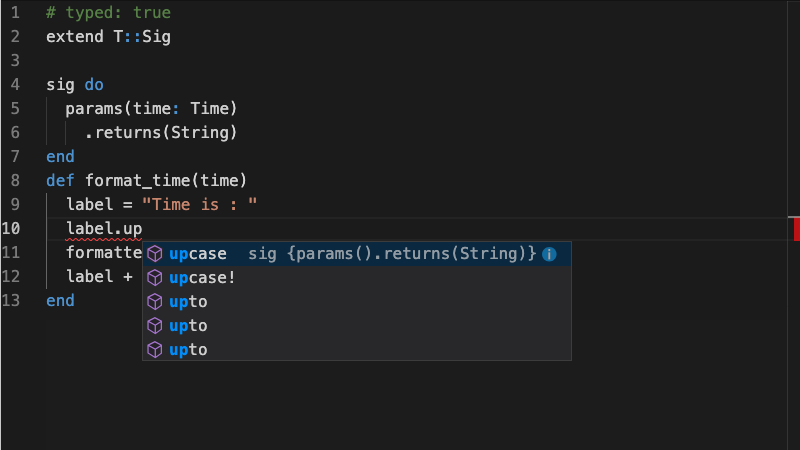
Sorbet is not only a type checker, it’s a tool suite around types. For example there is a LSP server, it enables developers to easily implement code autocomplete, go to definition and all kinds of nice things for different editors (Visual Studio Code, Atom, Sublime Text, Vim, Emacs…). So if you’re using Sorbet in your code and in your editor you will have a source of documentation already available that is always true.
These are pretty basic examples, but it can go further with Generics or Interfaces. It can even warn us of dead code.
I think Sorbet will really shine in large projects: it will reduce the fear of refactoring by providing instant feedbacks, it is a self-documenting method and it helps reuse someone else’s code. Sure it won’t remove testing but it can reduce some of it and will let us focus on what’s important (and not “What will happen if I put a String instead of an Array here?”).
The Ruby Community is very lucky to have such a big company investing so much effort in a type checker and willing to give it to the community (we are talking about more than 9 months of work by 3 very skilled people). If you want to know more, I really encourage you to check https://sorbet.org/ and to watch this video from Ruby Kaigi :
[1]: To handle some common Ruby metaprogramming techniques (code that generate code), Sorbet is able to “unroll” Ruby code, creating the metaprogrammed methods and type checking them. ↩
1) we run it in production;
— Dmitry Petrashko (@darkdimius) June 4, 2018
2) @nelhage measured overhead and the worst case(for method that does nothing) IIRC was under 5%;
3) `sig` supports one more builder method: `.checked(false)` to disable runtime checking;
4) runtime type system erases generics.