In the first of this series of blog posts about Data-Warehousing, I’ve been talking about how we use and manage our Amazon Redshift cluster at Drivy.
One of the most significant issues we had at this time was: how to isolate the compute from the storage to ensure maximum concurrency on read in order to do more and more data analysis and on-board more people in the team.
I briefly introduced Amazon Spectrum and promised to talk about how we were going to use it in a second blog post… But, that turned out not to be the case, because we ultimately decided to choose another data-warehousing technology (Snowflake Computing) which addresses the issue mentioned above, among other things, that I’ll expose here.
In Redshift and most of the Massive Parallel Processing SQL DBMS, the underlying data architecture is a mix of two paradigms:
This approach is convenient for homogeneous workloads: a system configuration that is ideal of bulk loading (high I/O, light compute) is a poor fit for complex analytical queries (low I/O, heavy compute) and vice versa.
When you deal with many consumers with different volumes and treatments you usually tend towards a multi-cluster organization of your data warehouse, where each cluster is dedicated to a workload category: I/O intensive, storage-intensive or compute-intensive.
This design gives more velocity to the teams. You can decide to have one cluster for each team, for example, one for the finance, one for the marketing, one for the product, etc. They generally no longer have resource related issues, but new kinds of problems could emerge: data freshness and consistency across clusters.
Indeed, multi-clustering involves synchronization between clusters to ensure that the same complete data is available on every cluster on time. It complexifies the overall system, and thus results in a loss of agility.
In our case we have thousands of queries running on a single Redshift cluster, so very different workloads can occur concurrently:
In order to improve the overall performance, to reduce our SLAs and make room for every analyst who wants to sandbox a complex analysis, we were looking for a solution that would increase the current capabilities of the system without adding new struggles.
It has to ensure the following:
Snowflake Computing meets all those requirements, it has a cloud-agnostic (could be Azure or AWS) shared-data architecture and elastic on-demand virtual warehouses that access the same data layer.
Snowflake is a pure software as a service, which supports ANSI SQL and ACID transactions. It also supports semi-structured data such as JSON and AVRO.
The most important aspect is its elasticity.
Storage and computing resources can be scaled independently in seconds. To achieve that, virtual warehouses can be created and decommissioned on the fly. Each virtual warehouse has access to the shared tables directly on S3, without the need to physically copy the data.
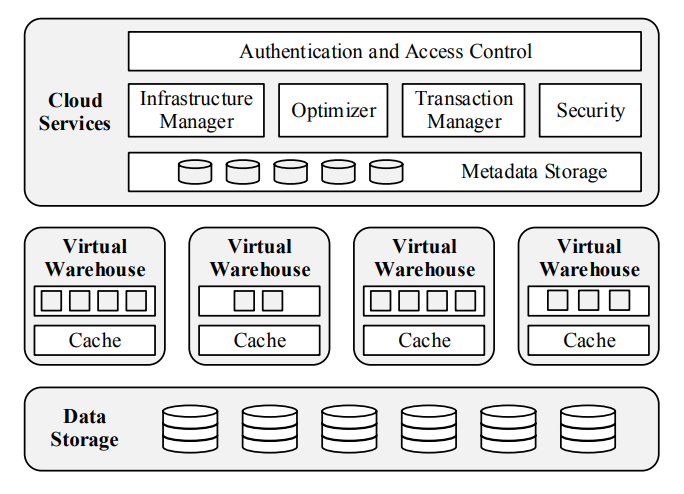
They also have two really interesting features: auto-suspend and auto-scale. Every time a cluster is not used for more than 10 minutes, it is automatically put in sleep mode with no additional fees. The “Enterprise” plan also gives the auto-scale feature that adapts the size of the virtual warehouse according to the workload (horizontal scaling). I haven’t tested this feature yet since we have the lower “Premier” plan.
The data engineering team at Drivy is composed of two engineers. We dedicated a full quarter to the migration on top of the day-to-day operations, and it’s not finished yet. During this migration, we took the opportunity to pay some of our technical debt and modernize some of our ETL processes.
One of the greatest improvements we addressed was the versioning on S3 of every data involved prior and post a transformation. At every run of every ETL pipeline, for instance, if we consider the bulk loading of the production DB, a copy of the raw data and the transformed data is stored on S3.
That gives us many new capabilities: reproducibility, auditing and easier operations (when backfilling or when updating a table schema).
The biggest blocks of the migration were:
We want to group similar workloads in the same warehouses, to tailor the resources needed to the complexity of the computations, we made the following choice in our first iteration:
| quantity | size | users | description | usage per day | usage per week |
|---|---|---|---|---|---|
| 1 | S | ETL + Viz | Main warehouse for bulk loading, ETL and visualizations software. | ∞ | 7d/7 |
| 1 | L | Exploration | Used early in the morning for ~100 high I/O extractions for an exploration software. | 0 - 4h | 7d/7 |
| 1 | XS | Analysts + Business users | Main warehouse for analysts, ~200 daily complex analytical queries. | 0 - 10h | 5d/7 |
| 1 | L | Machine Learning + Ops | Compute intensive warehouse for punctual heavy computations. | 0 - 2h | N.A. |
Every warehouse has the default auto-suspend set to 10min of inactivity.
Once we finish our migration, I’ll share my thoughts with you about the overall performance of the new system. I’ll also iterate on the mix of strategies presented above to ensure maximum velocity and convenience while minimizing the costs. Also, I’ll tell you more about how we do grant management.
Meanwhile, don’t hesitate of course to reach out to me if you have any feedback!