The GDPR has been around for several years now, and as advocates of data privacy, we are convinced by the legitimacy of such a regulation. However, as good as this measure is from a user’s perspective, it comes with its own puzzles and challenges for an online service provider… Here we’ll try to describe the solution we implemented to deal with the user’s data deletion, which is one of the rights granted by the GDPR (General Data Protection Regulation) to any European user of a service collecting personal data. As a result, this piece does not try to cover all the implications of the GDPR, nor does it pretend to bring a one size fits all solution deal with user data deletion.
GDPR specifies different roles and responsibilities. As an online service provider directly dealing with the end users, Getaround falls into the controller category. And as such we must comply with some obligations, notably:
In the description of the data usage, we define its processing and why the data is needed. The data retention is subject to 3 phases:
We can keep the data in an active database for the time necessary to execute the specific purpose for which it was collected. The data can be afterwards kept in an intermediate archive for a legitimate purpose (essentially to serve a legal obligation or when it corresponds to a user’s legal right) providing the archived data is only the one which is necessary for that purpose and access is strictly limited. Afterwards, we have to erase the data and can do it through full anonymization. These principles applying to data archiving and deletion prevent abusive data retention for an undetermined period “just in case”, and this also allows damage control in case of data leaks. Once data is fully removed from the system, it is “unleakable”. Similarly, the users are the primary owners of their data, so they can spontaneously ask for their personal data deletion.
This basically means the system must offer a way to delete a user’s personal details, whether upon their own request, or according to a time-based data expiration rule. While a manual solution can be acceptable for smaller systems, a large scale product such as ours requires a real technical solution.
Our service requires personal data from our users. We collect names, birth dates, id documents for driver vetting, etc. This is legitimate data to collect in a car rental context, and can be kept as long as it’s relevant (user is active, has some recent or upcoming rentals, has an ongoing claim, etc), but we must make sure that it’s thoroughly deleted when it’s no longer deemed relevant.
We also rely on 3rd parties (as per GDPR terminology) which process some of this data (for email campaigns, identity document authentication, customer support, etc.). The personal data communicated to these 3rd parties needs to be deleted when the user’s data is removed from our platform. Fortunately, most of these services also provide an API to automatically remove all data related to a user.
Finally, in the case where a user requests their account deletion, and some legal constraints force us to delay the actual data deletion, we must still make their account unusable and invisible to the other users or administrators.
Now that the legal context is laid out, let’s dive into the implementation. First, we tried to materialize the different needs under a formalized user account lifecycle.
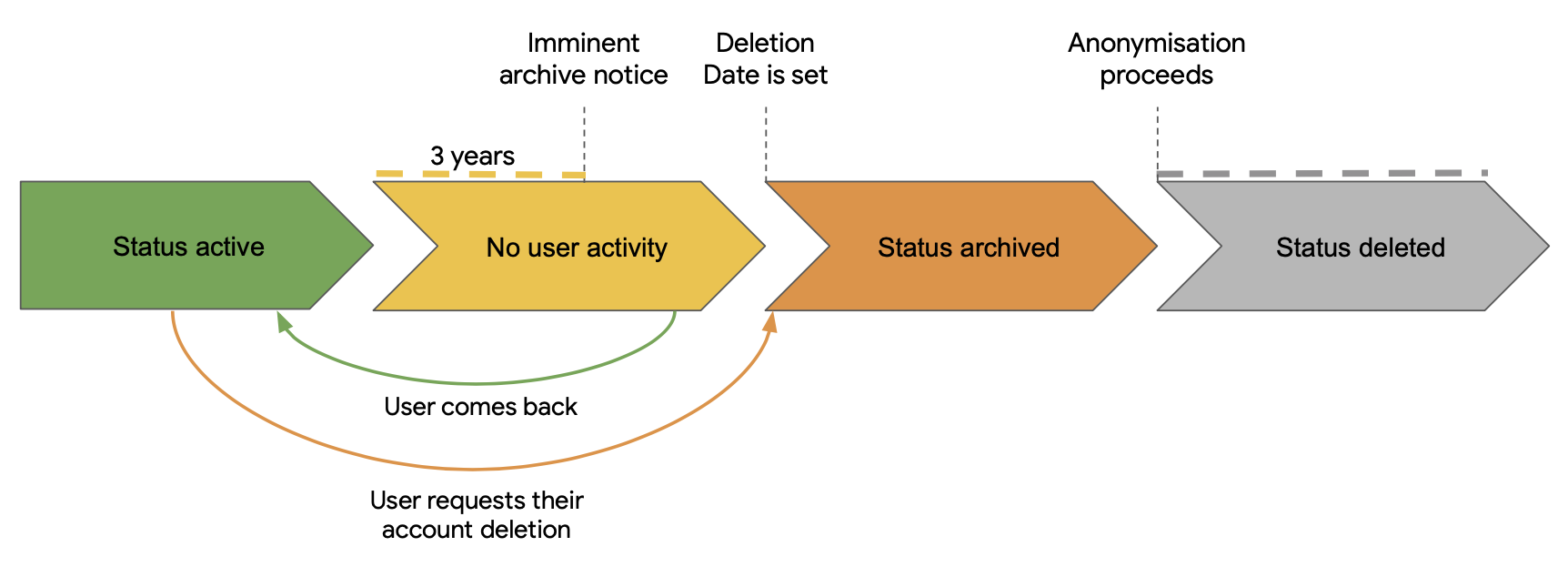
As illustrated, we have 2 paths to a user account’s deletion. A main passive one, and a spontaneous one when the user requests their own account deletion. The passive one is the nominal user lifecycle path:
The spontaneous account deletion happens upon the user’s own request. When they do so, the inactivity phase is skipped, and they are directly processed through the archiving phase, with the determination of the deletion date. Then the same process applies.
Once this lifecycle logic is laid out, the only remaining matter is the technical implementation.
We chose to define a dedicated model that holds the archiving and deletion logic. Let’s call it UserDeletionFlow, and define its attributes like this:
create_table :user_deletion_flows do |t|
t.references :user, null: false
t.string :state, null: false, index: true
t.datetime :archive_notice_email_sent_at
t.datetime :archive_after, null: false
t.datetime :archived_at
t.datetime :delete_after, null: false
t.datetime :deleted_at
t.timestamps null: false
t.index [:archive_after, :state]
t.index [:delete_after, :state]
end
A User has many UserDeletionFlow, but only one can be active at any time. The state column stores the state machine step where the UserDeletionFlow is. It applies the following sequence:
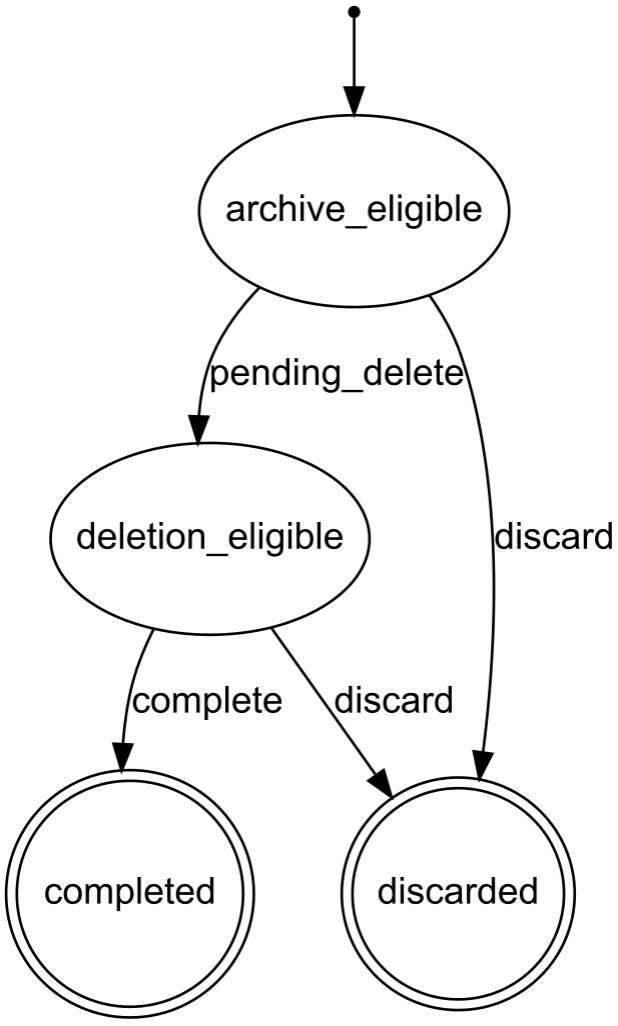
UserDeletionFlow is created with a state archive_eligible. An archive notice is sent to the user, and the current date is stored in archive_notice_email_sent_at. The archive_after date is set to 1 month later and stored.archive_after date is passed, the user’s latest activity is reassessed. If there was new activity, the UserDeletionFlow is discarded. Otherwise, the UserDeletionFlow state is set to deletion_eligible, and the delete_after date is computed based on several parameters and stored in the UserDeletionFlow.delete_after date is passed, the UserDeletionFlow state is set to completed, and an anonymization process takes over to erase the user’s data.These steps are preformed by nightly cron jobs that query the database to retrieve all impacted accounts. If a user spontaneously requests the deletion of their data, their related UserDeletionFlow is immediately created in the deletion_eligible state, and the delete_after column is populated similarly to the passive deletion flow.
When a user account gets deleted, we immediately create N DataDeletionAttempt for N user “areas”, and trigger asynchronous jobs to actually perform these DataDeletionAttempt. We have designed several data erasers, each taking care of anonymizing a specific area of the user’s data. They fall into 2 categories:
Each of these bears the responsibility to anonymize one specific area of the user data stored in our database. For instance, there is an eraser for the user’s identity (users.first_name, users.last_name, users.birth_date,…), another one for the user’s cars (cars.registration_plate, cars.vehicle_identification_number, etc.). The erasers anonymize the data by replacing them with placeholders, either static or randomly generated, so that the database constraints and referential integrity are respected.
And since we’re using PaperTrail on some models to keep an audit trail of the changes that are applied, these erasers also have the responsibility to anonymize the versions that tracked some personal data changes.
Finally, some of these erasers remove the possible files that were stored for the deleted account.
These erasers are clients to our 3rd party providers’ APIs, and request their users endpoint to request the user’s data deletion.
All erasers are run asynchronously, and some of the 3rd party erasers need a personal identifier from our database. For instance, to erase a user’s history on Zendesk, we first need their Zendesk identifier, which we can get by searching for the user’s email on Zendesk API. But it can happen that the user’s email has already been erased when the Zendesk eraser runs. To address this situation, we denormalize some deletion arguments into the related DataDeletionAttempt. When the eraser succeeds, this denormalized data is of course nullified to guarantee the full removal of personal data.
If any data eraser fails for any reason, we are notified on our bug tracking system, and we make sure to address the situation.
This solution took some time to implement and still has room for improvement, but we are satisfied with the upside it already brings. It’s fully automated, flexible and easy to maintain. More importantly, we take some pride in continuously working on improving our compliance with European regulation requirements and make sure we provide a platform which is respectful of our users’ privacy.