The Exchangeable Image File Format (EXIF) is a standard that specifies formats for images and sounds. It stores technical details through metadata, data that describes other data, such as the camera make and model and the date and time the image was taken.
Initially, EXIF was used for two image formats, JPEG and TIFF. But today, other file formats such as PNG, WEBP, or HEIC also support EXIF for metadata.
This article will focus on the JPEG format. In the first part, we will explore its structure before seeing how to read and update associated metadata through Javascript in a browser environment.
Before moving on, it is essential to review some key concepts:
📌 What is the 0x notation?
0x indicates that the following number is in hexadecimal format, which uses a base-16 number system (as opposed to the base-10 decimal system). This notation is case-insensitive, meaning that 0XFF and 0xff are exactly the same.
📌 What is a bit or a byte? In computer science, a bit is the smallest and the most basic unit of information. It is a binary digit (base 2) representing 0 or 1. A byte (or octet) is a group of eight bits. Since there are 256 possible combinations of 8 bits, a byte can be expressed as a hexadecimal number. For example:
0x00 represents 0 in decimal and corresponds to 0000 0000 in binary, which is the minimum 8-bit value.0xD8 represents 216 and corresponds to 1101 1000.0xFF represents 255 and corresponds to 1111 1111, which is the maximum 8-bit value.For multiple-byte words, the hex numbers are just combined: 0xFFD8 is a two-byte word, and 0x45786966 is a four-byte word.
📌 What is Endianness? This is how a set of bytes is stored in memory. In big-endian, the most significant byte (leftmost) comes first, while in little-endian, the least significant byte (rightmost) comes first.
For example, let’s consider the two-byte word 0x0124. In a big-endian system, it will be written as 01 24, whereas in a little-endian one, it will be written as 24 01. Knowing whether an image has been written on a big or little-endian device is essential to read its data correctly.
The structure of a JPEG image is divided into parts marked by two-byte markers, always starting with a 0xFF byte. Below is a list of key markers found in the pages 20/21 of the JPEG compression specification:
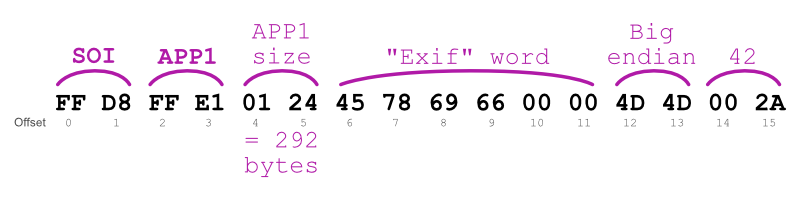
0xFFD8: SOI (Start of Image); indicates the beginning of the image structure.0xFFE*n*: APPn (Application-related tags); following the SOI marker, with n between 0 and F (full list). For example, APP11 (or 0xFFEB) is for HDR data, APP13 (or 0xFFED) for Photoshop and APP1 (or 0xFFE1) for EXIF.0xFFDA: SOS (Start of Scan); indicates the beginning of the image-related data.0xFFD9: EOI (End of Image); indicates the end of the image.The first four file bytes, here FF D8 FF E0 for JPEG, are also known as magic numbers and are used by software to identify the file type.
The size of a segment can be determined by reading the two bytes following its marker. For example, if the segment starts with FFE1 0124 XXXXXXX, then the APP1 segment size is 292 bytes, with 0124 being the size’s hexadecimal representation.
Data in JPEG structure is grouped into directories called IFDs. For example, IDF0 is located in the APP1 segment, and IFDExif is a sub-IFD of IDF0.
The IFD dataset includes a two-byte word indicating the number of tags, followed by the tags data and ending with the four-byte offset of the next IFD (or 0 if none).
A tag, like all EXIF tags, is a twelve-byte length sequence made up of:
1 for a BYTE (one-byte integer), 3 for a SHORT (two-byte integer), or 4 for a LONG (four-byte integer). For further details, see the pages 25 and 26 of the JPEG compression specification.SHORT values, two bytes are read; for LONG values, four bytes are read. If the value is longer than four bytes (e.g., RATIONAL type), these four bytes store the offset needed to reach the actual value.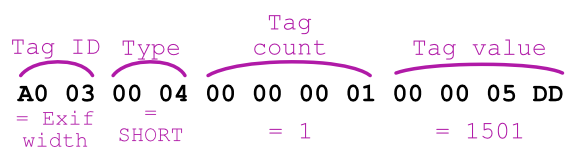
Time to code! The FileReader API is here used to read the image as a buffer. Then it is transformed into a DataView for easier byte manipulation.
The next step is to examine the start of the JPEG structure, which should be the SOI marker:
// Where the final image with updated metadata will be stored
let finalImageBlob = null
const reader = new FileReader()
reader.addEventListener("load", ({ target }) => {
if (!target) throw new Error("no blob found")
const { result: buffer } = target
if (!buffer || typeof buffer === "string") throw new Error("not a valid JPEG")
const view = new DataView(buffer)
let offset = 0
const SOI = 0xFFD8
if (view.getUint16(offset) !== SOI) throw new Error("not a valid JPEG")
// Here will happen the image metadata manipulation
})
// Image given as a Blob, but readAsArrayBuffer can also take a File
reader.readAsArrayBuffer(imageBlob)Note: The getUint16 function in Javascript is used to read two bytes (2*8 = 16bits), and there is a similar function for four bytes, getUint32.
From here can begin the loop through the image data to locate the EXIF section. The EXIF segment uses the APP1 marker followed by a special six-byte ASCII code Exif (0x457869660000) immediately following the APP1 size data.
Reaching SOS marker is reached means reaching the start of the image data so the end of the metadata section.
const SOS = 0xFFDA
const APP1 = 0xFFE1
// Skip the last two bytes 0000 and just read the four first bytes
const EXIF = 0x45786966
let marker = null
// The first two bytes (offset 0-1) was the SOI marker
offset += 2
while (marker !== SOS) {
marker = view.getUint16(offset)
const size = view.getUint16(offset + 2)
if (marker === APP1 && view.getUint32(offset + 4) === EXIF) {
// EXIF segment found!
// Following code will be here
}
// Skip the entire segment (header of 2 bytes + size of the segment)
offset += 2 + size
}The last thing to do here is to determine which is the endianness used to encode that image. In the JPEG structure, the endianness is provided thanks to the two-bytes word following the Exif special word. If the word is 0x4949, it means it’s little endian, otherwise it is 0x4D4D for big endian. This endianness data must be followed by the two bytes 0x002A (42 in decimal).
Note: From now on, always provide the endianness to the getUint16/getUint32 functions to correctly read the bytes.
const LITTLE_ENDIAN = 0x4949
const BIG_ENDIAN = 0x4d4d
// The APP1 here is at the very beginning of the file
// So at this point offset = 2,
// + 10 to skip to the bytes after the Exif word
offset += 10
let isLittleEndian = null
if (view.getUint16(offset) === LITTLE_ENDIAN) isLittleEndian = true
if (view.getUint16(offset) === BIG_ENDIAN) isLittleEndian = false
if (!isLittleEndian) throw new Error("invalid endian")
// From now, the endianness must be specify each time bytes are read
// The 42 word
if (view.getUint16(offset + 2, isLittleEndian) !== 0x2a) throw new Error("invalid endian")If APP1 appears at the very beginning of the image structure (which is usually the case), then the structure should be as follows:
All the necessary information are now known to search for the EXIF tags:
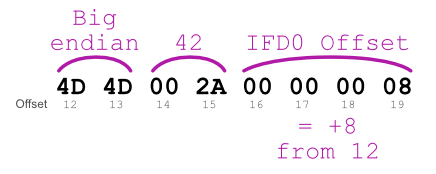
Orientation, located in the IFD IFD0ExifImageWidth or PixelXDimension tag, located in the IFD IFDExif, provided by the ExifOffset tag of IFD0ExifImageHeight or PixelYDimension tag, also located in IFDExifTo locate the IFD0, its offset is given by the 4-byte word immediately after the endianness 42 number.
This sequence that includes the endianness two-byte word, 42, and the IFD0 offset four-byte word is commonly referred to as the “TIFF (Tagged Image File Format) Header”:
At this point, there are two tags that need to be found through the IFD0 data:
Orientation tag (hex 0x0112) which is a SHORT value that must be replaced by 1ExifOffset tag (hex 0x8769) which is a LONG value allowing to find the EXIF IFD tagsAs mentioned earlier, the first two-byte word of the IFD indicates the number of tags in the IFD. Since each tag is 12 bytes long, multiplying the number of tags by 12 gives the size of all the IFD tags, allowing for looping through them.
const TAG_ID_EXIF_SUB_IFD_POINTER = 0x8769
const TAG_ID_ORIENTATION = 0x0112
const newOrientationValue = 1
// Here offset = 12
// IFD0 offset given by the 4 bytes after 42
const ifd0Offset = view.getUint32(offset + 4, isLittleEndian)
const ifd0TagsCount = view.getUint16(offset + ifd0Offset, isLittleEndian)
// IFD0 ends after the two-byte tags count word + all the tags
const endOfIFD0TagsOffset = offset + ifd0Offset + 2 + ifd0TagsCount * 12
for (
let i = offset + ifd0Offset + 2;
i < endOfIFD0TagsOffset;
i += 12
) {
// First 2 bytes = tag type
const tagId = view.getUint16(i, isLittleEndian)
// If Orientation tag
if (tagId === TAG_ID_ORIENTATION) {
// Skipping the 2 bytes tag type and 4 bytes tag count
// Type is SHORT, so 2 bytes to write
view.setUint16(i + 8, newOrientationValue, isLittleEndian)
}
// If ExifIFD offset tag
if (tagId === TAG_ID_EXIF_SUB_IFD_POINTER) {
// Type is LONG, so 4 bytes to read
exifSubIfdOffset = view.getUint32(i + 8, isLittleEndian)
}
}Note: Following the same logic as for reading, the setUint16/setUint32 functions are used to respectively write two or four bytes.
Once the offset of the EXIF sub-IFD is found, a new loop must be executed through that IFD’s data to find the remaining height and width tags.
Here is information about the two tags that need to be replaced:
ExifImageWidth or PixelXDimension tag (hex 0xa002), a LONG value that must be replaced by 1920ExifImageHeight or PixelYDimension tag (hex 0xa003), a LONG value that must be replaced by 1080As a reminder of what was previously stated, the IFD tag is composed of 2 bytes for the type, 4 for the count, and 4 for the value.
const TAG_ID_EXIF_IMAGE_WIDTH = 0xa002
const TAG_ID_EXIF_IMAGE_HEIGHT = 0xa003
const newWidthValue = 1920
const newHeightValue = 1080
if (exifSubIfdOffset) {
const exifSubIfdTagsCount = view.getUint16(offset + exifSubIfdOffset, isLittleEndian)
// This IFD also ends after the two-byte tags count word + all the tags
const endOfExifSubIfdTagsOffset =
offset +
exifSubIfdOffset +
2 +
exifSubIfdTagsCount * 12
for (
let i = offset + exifSubIfdOffset + 2;
i < endOfExifSubIfdTagsOffset;
i += 12
) {
// First 2 bytes = tag type
const tagId = view.getUint16(i, isLittleEndian)
// Skipping the 2 bytes tag type and 4 bytes tag count
// The two types are LONG, so 4 bytes to write
if (tagId === TAG_ID_EXIF_IMAGE_WIDTH) {
view.setUint32(i + 8, newWidthValue, isLittleEndian)
} else if (tagId === TAG_ID_EXIF_IMAGE_HEIGHT) {
view.setUint32(i + 8, newHeightValue, isLittleEndian)
}
}
}Getting the final image is as simple as building a new Blob from the updated buffer data:
finalImageBlob = new Blob(view)In the end, the updated blob can be converted to a file or downloaded, depending on the application’s needs.
This article covers the basics of reading and updating tags, but you can expand the code by adding more tags. All the hex codes for the tags can be found on exiftools.org or this tags reference site.
It’s worth noting that there are existing libraries like exif-js or piexifjs for manipulating EXIF data, but they may be larger than what is needed here and seems not being actively maintained.
If you want to see the full code used to write this article, feel free to check out this gist.