At Drivy, we store, process and analyse hundreds of gigabytes of data in our production systems and our data warehouse. Data is of utmost importance to us because it makes our marketplace run and we use it to continuously improve our service.
Making sure that the data we store and use is what we expect is a challenge. We use multiple techniques to achieve this goal such as high standard coding practices or checker jobs we run on production data to make sure that our assumptions are respected.
There are several research papers discussing the data quality dimensions as professionals have a hard time agreeing on the terminology. I found that the article written by the DAMA UK Working Group successfully defines 6 key dimensions that I summarize as follows:
For example in a log database, uniqueness does not always need to be enforced. However, in another table aggregating these logs we might want to enforce the uniqueness dimension.
My main goal was to enforce a high quality of data in our data warehouse, which we fill with standard ETL processes.
For our web application, we already have checker jobs (we talked about this in this blog post) in the context of a monolith Rails application with MySQL databases. They are somewhat simpler: they run on a single database and check the quality of data we have control over because we wrote code to produce it. We can also afford to perform migrations or backfill in case we detect a corruption and want to fix the data.
When working with ETL processes and in the end a data warehouse, we have different needs. The main issue we face is that we pull data from various databases, third parties, APIs, spreadsheets, unreliable FTPs connections etc. Unfortunately, we have little or no control over what we fetch or collect from these external systems. Working with external datasources is a hard challenge.
We ingest raw data, we build aggregates and summaries, and we cross join data. Freshness depends on the source of the data and how we extract it. We don’t want alerts on data that is already corrupted upstream (this point is debatable), but we want to know if an upstream datasource gets corrupted. We usually want to compare datasets side by side (especially when pulling from another database) to make sure that the consistency dimension is respected.
Overall, I find it hard to enforce a strict respect of all data quality dimensions with 100% confidence, as data we pull upstream will never fully respect what was advertised. Data quality checkers can help us in improving our data quality, make sure preconditions hold true and aim for better data quality in the long run.
Now that we have a clearer idea about what data quality dimensions are and what we want to achieve, we can starting building something. My goal was to be able to perform checks to prove that data quality dimensions are respected. I had to come up with high-level abstractions to have a flexible library to work with and this research article helped me.
My key components can be defined as follows:
Data quality checks are performed at a specified interval on one or multiple datasets that are coming from various datasources, using predicates we define. Checks have a tolerance and trigger alerts on alert destinations with an alert level defined by the severity of the found errors.
Let’s define each word used here:
Checkers are the most important components of the system. They actually perform the defined data quality checks on datasets. When implementing a new checker, you write a subclass from one of the abstract checkers supporting the core functionalities (extraction types, alert destinations, alert levels, logging etc.)
Available checkers:
We rely on Apache Airflow to specify, schedule and run our tasks for our data platform. We therefore created a pipeline putting together the data quality checks library with Airflow tasks and scheduling capabilities to easily run checks.
The main pipeline is executed every 15 minutes. Each data-quality check is composed of 2 main tasks:
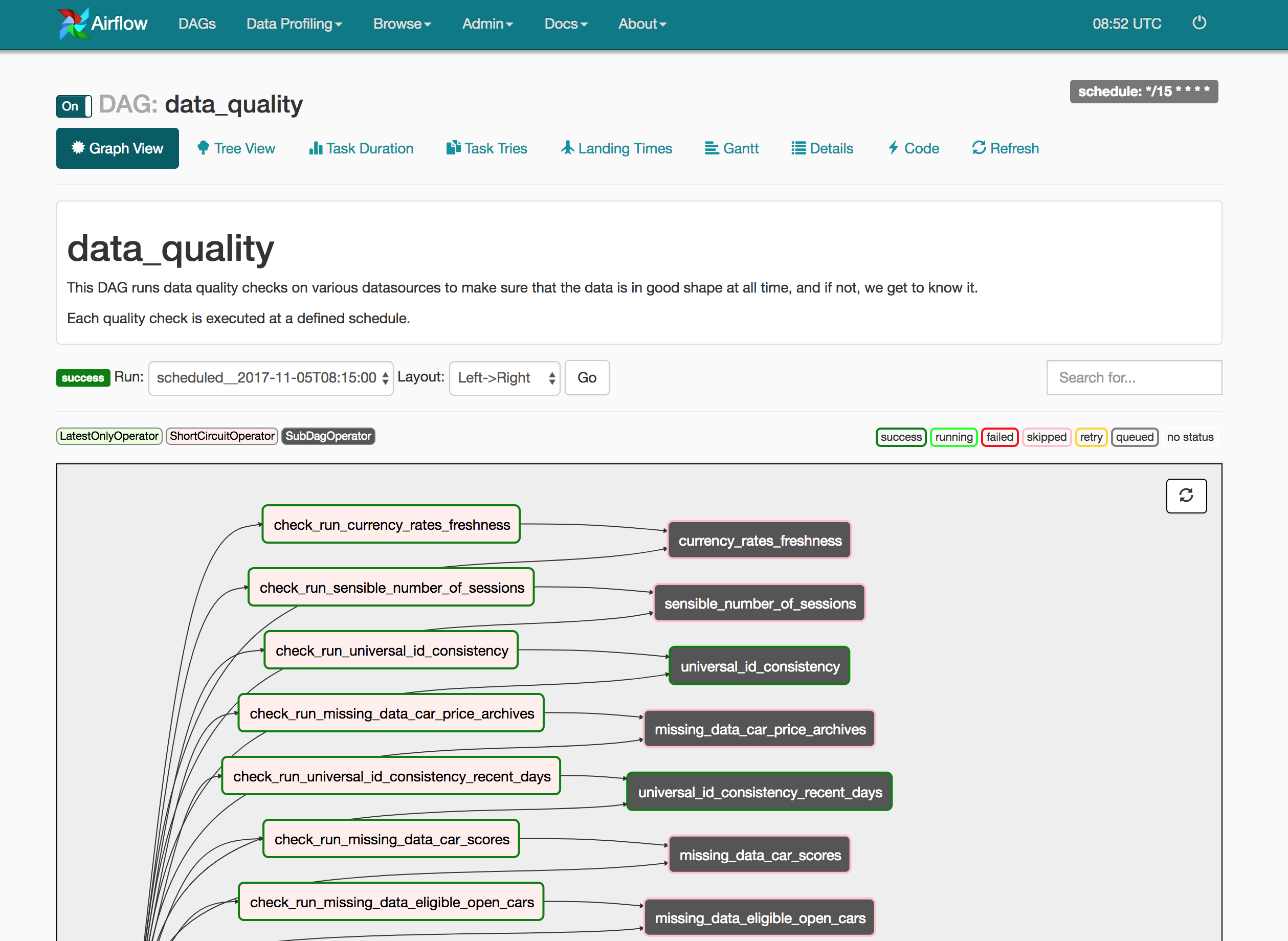
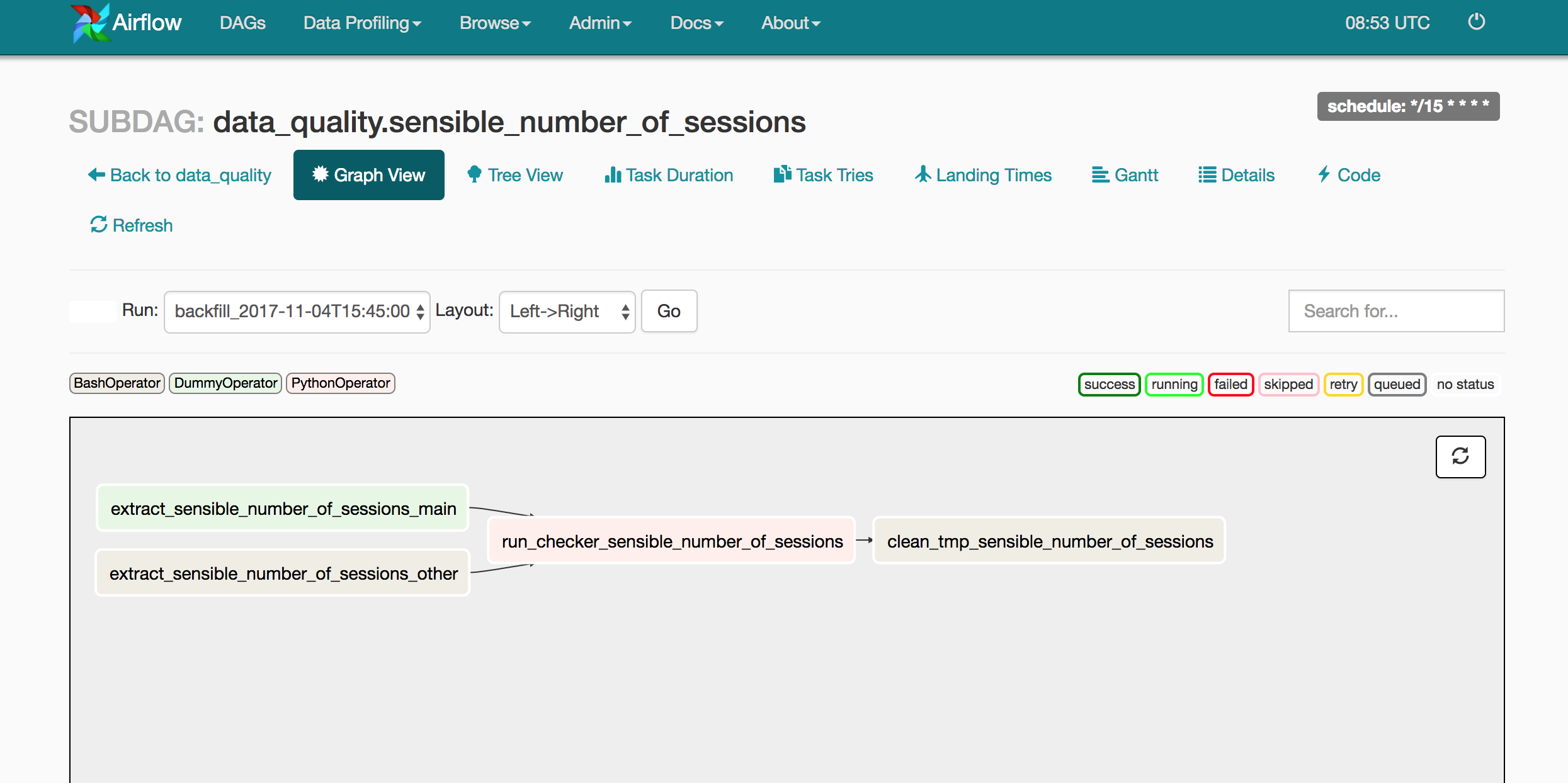
When a check is executed and detects a malfunction, we get alerted. For now on we only use Slack, but there is room for other alerters such as text messages, PagerDuty or emails.
When an alert triggers, we get to know what’s the alert, what’s the purpose of the associated check, how important the alert is with the number of falsy elements etc. Remember that alerts can have a certain level of tolerance - some errors can be tolerated - and different alert levels to help triage alerts. We get a quick view of data points which failed the check to have a rough idea about what’s going on, without jumping to the logs or looking immediately at the dataset.
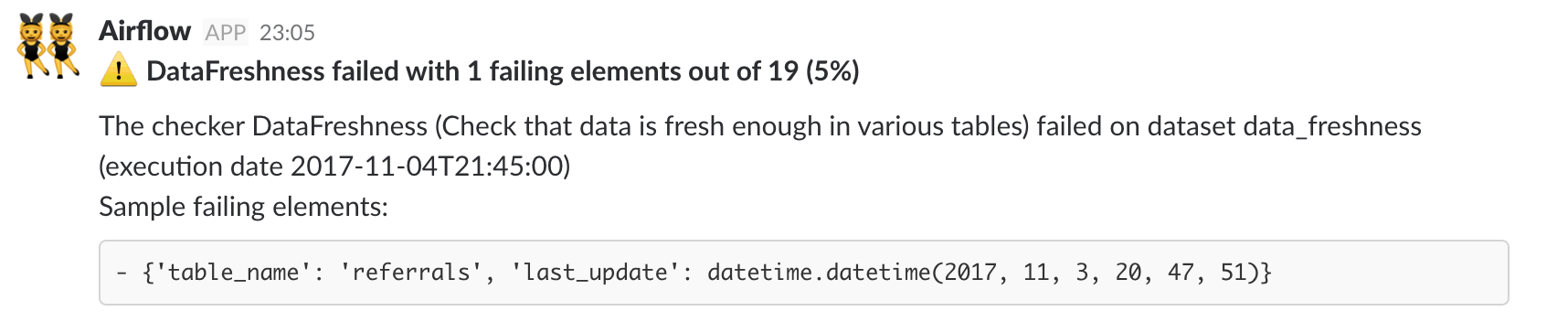
If we need to investigate further, we can look at the logs in Airflow or inspect the raw dataset. We find it convenient to have alerts in Slack so that we can start threads explaining why an alert triggered and if we need to take actions.
We’ve been using these data quality checks over the last 3 months and we’ve been really happy to have them. It makes us trust more our data, helps us detect issues or prove that assumptions are indeed always respected. It’s also a good opportunity to step up our data quality level: we can lower thresholds over time, review SLAs and put more pressure on the level of confidence we have in critical parts of our storage.
For now, we plan to add more checkers (we have currently 20-30 checkers) to see if we’re happy with what we have, improve it and keep building on it.
We thought about open sourcing what we built, but we think that it’s a bit too soon and we want to gain more confidence before publishing it on GitHub.
If data quality is of interest to you and you want to react to this blog post, I would be thrilled to hear from you! Reach out on my Twitter.
To get an idea of what a data quality checker looks like, here is a sample quality check which checks if data is fresh enough for various tables in our data warehouse (Redshift). This class can easily be tested, to have automated tests proving that alerts trigger with specific datasets.
This class is complete enough so that Airflow can know how to extract data from Redshift, transform and run the check automatically.
# -*- coding: utf-8 -*-
import datetime
from datetime import timedelta
from data_quality.alert_levels import FailingElementsThresholds
from data_quality.checkers import PredicateSingleDatasetChecker
from data_quality.tolerances import LessThan
from data_quality_checks.base_checkers.base import BaseQualityCheck
from data_quality_checks.base_checkers.base import DatasetTypes
from data_quality_checks.base_checkers.base import ExtractionTypes
from data_quality_checks.base_checkers.base import ScheduleTypes
class DataFreshness(BaseQualityCheck):
# Run a query on Redshift
EXTRACTION_TYPE = ExtractionTypes.REDSHIFT_QUERY
# Dataset can be parsed from a CSV
DATASET_TYPE = DatasetTypes.CSV
SCHEDULE_TYPE = ScheduleTypes.CRON
CRON_SCHEDULE = '20,50 7-22 * * *'
def alert_level(self):
# 0-2: warning
# 2-3: error
# > 3: critical
return FailingElementsThresholds(2, 3)
def tolerance(self):
# Get notified as soon as we have a single issue
return LessThan(0)
def description(self):
return 'Check that data is fresh enough in various tables'
def checker(self, dataset):
class Dummy(PredicateSingleDatasetChecker):
def __init__(self, dataset, predicate, options, parent):
super(Dummy, self).__init__(
dataset, predicate, options
)
self.parent = parent
def checker_name(self):
return self.parent.__class__.__name__
def description(self):
return self.parent.description()
fn = lambda e: e['last_update'] >= self.target_time(e['table_name'])
return Dummy(
dataset,
fn,
self.checker_options(),
self
)
def freshness_targets(self):
conf = {
5: config.FINANCE_TABLES,
8: config.CORE_TABLES,
24: config.NON_URGENT_TABLES
}
res = []
for lag, tables in conf.iteritems():
for table in tables:
res.append({'table': table, 'target': timedelta(hours=lag)})
return res
def freshness_configuration(self, table):
targets = self.freshness_targets()
table_conf = [e for e in targets if e['table'] == table]
if len(table_conf) != 1:
raise KeyError
return table_conf[0]
def target_time(self, table):
now = datetime.datetime.now()
lag = self.freshness_configuration(table)['target']
return now - lag
def query(self):
parts = []
for table_conf in self.freshness_targets():
query = '''
SELECT
MAX("{col}") last_update,
'{table}' table_name
FROM "{table}"
'''.format(
col=table_conf.get('col', 'created_at'),
table=table_conf['table'],
)
parts.append(query)
the_query = ' UNION '.join(parts)
return self.remove_whitespace(the_query)