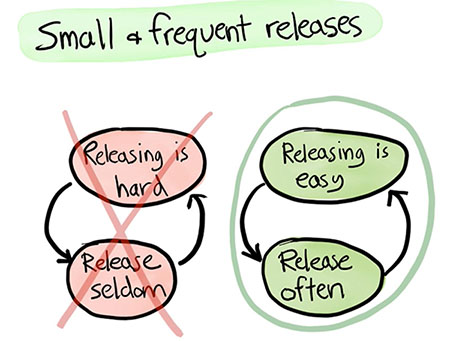
We’ve always valued releasing quickly, as unreleased code is basically inventory. It slowly gathers dust and becomes outdated or costs time to be kept updated. Almost 3 years ago we published an article “Drivy, version 500!” on our main blog, so I feel now is the time to get more into the details of how we accomplish pushing a lot of new versions of the app to production.
As in most cases, we keep 改善 in mind and go for continuous improvement over one huge definitive solution straight away. We don’t try to build the perfectly automated system that handles all cases, when there are only 2 developers and no users. Probably obvious, but it’s something always worth repeating.
In this article I’ll try to explain chronologically all the steps we went through over the course of 5 years, so as to showcase the evolution of our tools and processes. Of course if you want to see how we do it now, go straight to the last step… but it might already be outdated by the time you read this!
Drivy used to be in PHP, but for various reasons we decided to move away from it and use Ruby on Rails. At this point we started creating automated tests for everything we were doing, and have kept adding to our test suite since then. This is very important because without automated tests, you will never be able to release often whilst avoiding major bugs.

As far as pushing to production was concerned, we tended to basically do nothing about automation, and would just release manually after running to the specs on our machines. This was fine because we were not a lot of developers and therefore didn’t move too quickly, and there were not too many specs yet so the build was fast.
Note that I don’t mention Capistrano or similar tools. This is because we are hosted on Heroku, and they provide their own simple toolbelt for deployment. However, if we were not using this provider, I feel like the minimal first step would be setting up something like Capistrano.
Quickly we developed a simple process loosely inspired by Kanban and based on Github tags and Huboard to be able to visualize progress. This would allow us to quickly see if a given commit could be deployed or not, and therefore to release faster without the need for additional back and forth.
To do so we started linking every commit to issues and used tags such as:
Closing an issue would mean “the ticket has been proved to be successful in production, with no bugs or regressions of any kind”.
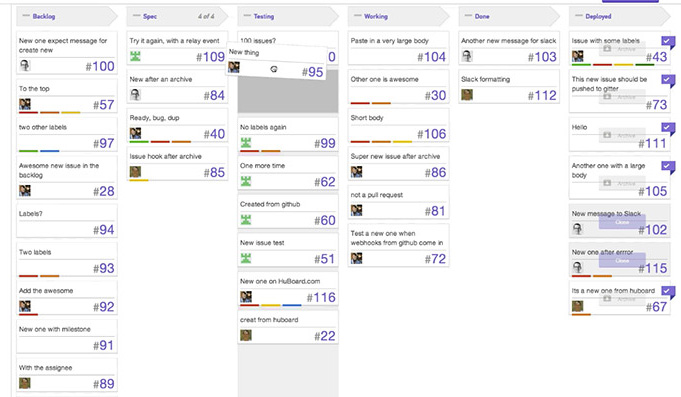
Since then we moved from Huboard to waffle which was more stable and quicker, but there are tons of options out there nowadays including Zenhub or Github project boards.
At this point we were already half a dozen developers and we needed simple ways to share information with newcomers. We started adding and maintaining more documentation on the important parts of the release process.
Releasing code might also imply changing the database schema, which can get tricky. Rails makes it easier since it uses migrations, but we’ve added a couple of ground rules in order to be effective:
Never edit/remove a migration file that has been merged into master. Add new migrations instead.
Commit the migration file (and schema.rb) in its own commit if the migration needs to be done in two steps. There shouldn’t be other files in the commit. This makes it easier to do a zero-downtime deployment.
There are a lot of articles and resources on how to do zero downtime deployments, so I won’t get into details here, but know that’s something required in order to ship fast.
After a bit we added Jenkins, a continuous integration server. It would run on a spare mac mini in the open space. This was a good improvement because it would help make sure we always ran tests and that any red build would be noticed.
Jenkins also had the great advantage of deploying to our staging environment right after a succesfull build.
Since we already had a documented flow to release and a Jenkins server, it was only a matter of time until we could automate it. The thing that made us decide to automate was the fact that, with people joining the team, we were afraid that it would slow down releases and create larger and therefore riskier releases.
To achieve this we created a simple shell script that could be run by Jenkins at the press of a button. It would go through all the documented steps to release, except automatically!
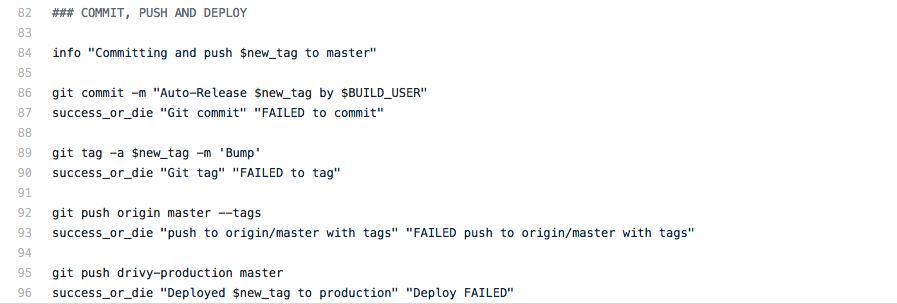
Note that all this time we would often look back at the data and see how we were doing in term of number of releases.
Releasing quickly proved to be steadily improving the way we worked, and reduced the risk of bugs. However there were cases where we could not deploy to all users right away. To deal with this issue, we added a feature flipper feature using the appropriately named flipper gem.
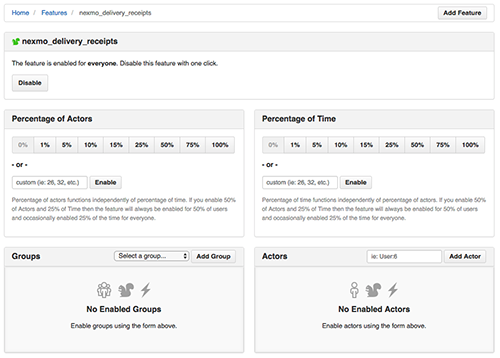
This allowed us to release code that we didn’t intend to use right away, or that we wanted to offer only to a subset of users. It was a great way to decorrelate the “technical” release from the “product” release.
After a while with this setup, we started to see some limitations. We didn’t want to invest a lot of time managing Jenkins, but the machine would sometime go down, there would be random hardware issues and making sure to apply software updates were a pain.
We decided not to invest more energy into Jenkins and instead move to a cloud solution. At this time CircleCI looked like a great option. So after properly benchmarking all other competitors, we dropped Jenkins and started using CircleCI.
CircleCI also provides additional functionalities out of the box. One particularly interesting feature is to add multiple containers in order to increase parallelization when running specs, thereby speeding up the test suite.
Since CircleCI didn’t provide a way to manually trigger a release, we had to build a bit of instrumentation and it took the form of a command line interface tool.
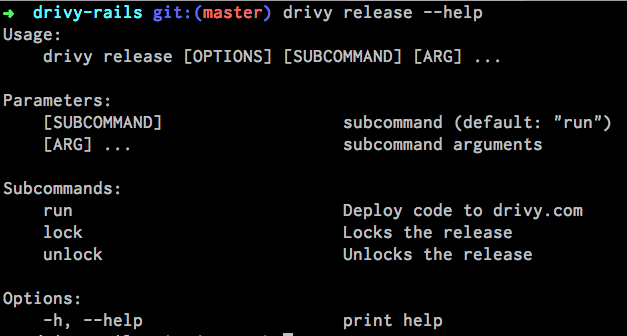
This was fairly easy to develop using clamp and we integrated it as a gem in our project so that every developer could release easily.
When needed, we would build small tools like a chrome extension to be able to better visualize in github was was about to get released using a URL looking like this:
https://github.com/ORG/REPO/compare/last_release...master
As we grew and shipped faster, we needed to make sure we weren’t introducing regressions. We were adding automated tests of course, but this doesn’t prevent every possible issue, so we improved the way we were monitoring and fixing bugs.
If you’d like to know more about this, we actually have an entire article dedicated to it: Managing Bugs at Drivy.
As time passed we improved with a Slack integration for notifications, a GitHub integration for automatic updates on issues and much more.


This proved to be very useful and made the act of releasing more or less painless.
We were using git-flow, but it felt way too complicated compared to what we actually needed. We decided to streamline the process, making releases even simpler to understand. This was detailed in this article: “Simple Git Flow With Heroku Pipelines”.
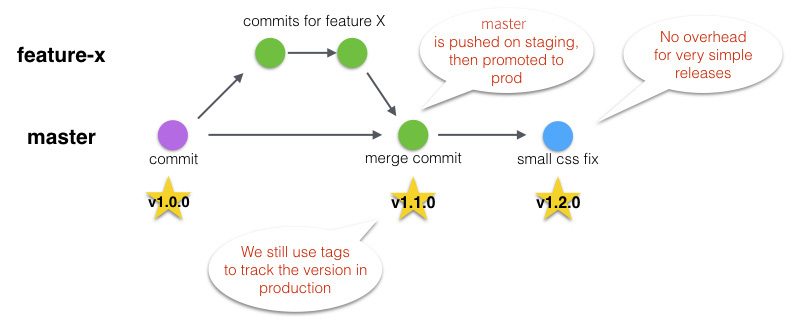
We also worked on making even smaller incremental releases than before, splitting work into individual and releasable commits. This made releases easier, and if you’d like to know more you can check out this article: “Best Practices for Large Features”
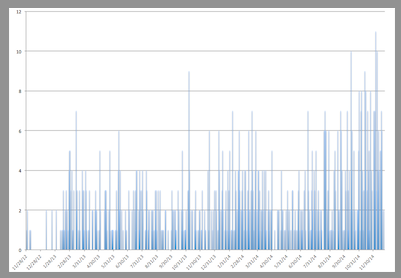
Since we prefer looking at data rather than staying in the dark, we added more information about the different steps of our release process. This way we now have a nice graph in Grafana with the number of releases we are making per week:
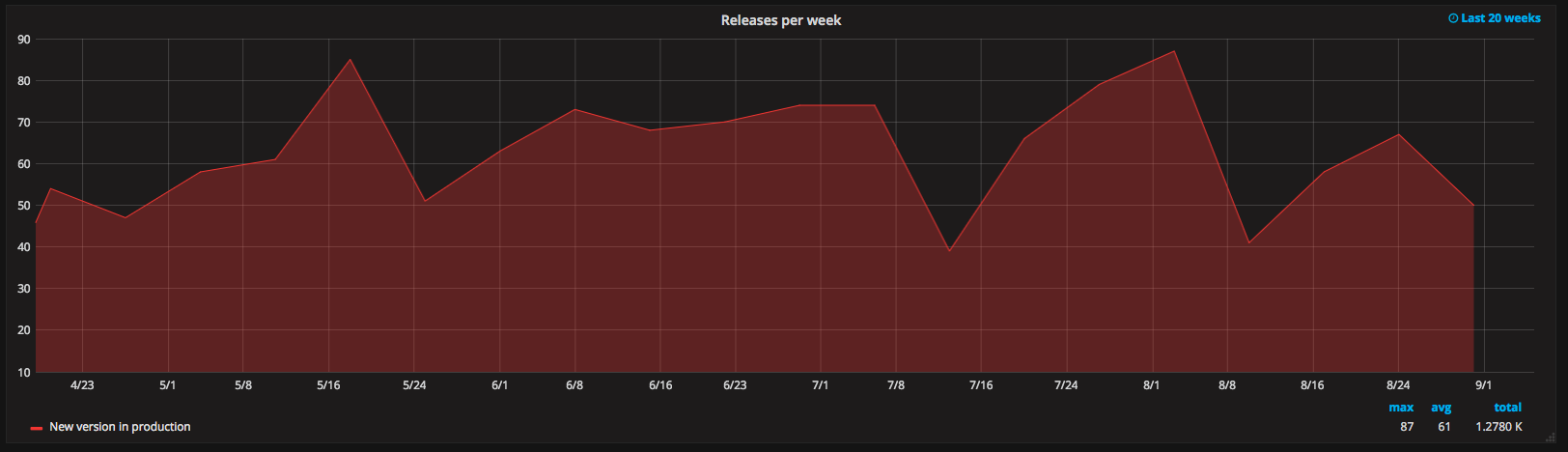
As we grew, the engineering team got larger and it lead to reduced agility. We worked on a new organisation based on Spotify’s squads and it helped us move even faster than before, which was visible in the number of releases.
After years spent adding on to the test suite, we started to feel that the build time was slowing us down, clocking in at approximatively 15 minutes. At this point CircleCI released a new version that allowed us to tweak our build better thanks to Docker, so we integrated it and saw great improvements on build speed.

Once again growth caused us to change our way of working. Now with more developers than ever in the team, there are more questions to be answered: about access rights, enforcing certain constraints, making internal contributions to the tooling easier…
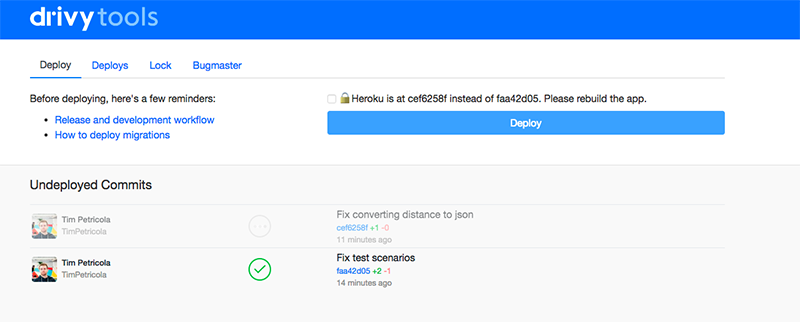
This is why we introduced our new Drivy Tool app, strongly inspired by Shopify’s shipit. This allowed us to better control credentials and improve onboarding as there is nothing to install: just login using Github and use the app!
Splitting the app into a lot of micro services could improve release rate as well. However this is quite costly to do, so we plan on extracting services on an as-we-go and if-appropriate basis. We don’t feel any pain (yet), so there is no need to make a big technical move.
As you can see we went through a lot of iterations, involving new tools, changes in processes and more. Nowadays we release to production close to 10 times a day, with very few regressions.
I can’t say enough how central a good test suite is to any continuous integration process. If you can’t catch regressions or new bugs quickly, there is no chance you can implement such a process.
Same goes for good and simple processes. There’s no need to go overboard with red tape… but effective, structured and documented ways of doing things will help with productivity. It’s also great for onboarding new and more junior developers.