It is very important to have a minimal number of bugs in production. I would love to say that we have absolutely no issues, but problems are bound to happen and it’s really a matter of reducing risk. The question is really about how fast and how efficiently can you react.
First we need to know if there are any problems. The more obvious solution is to be reactive to any user reports, this is why we have a dedicated Slack channel so that the customer support team can let us know about any issues:
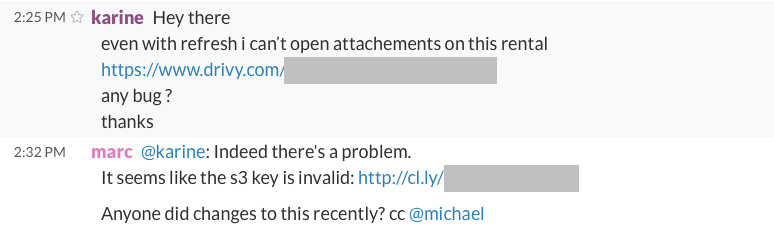
This is a very simple and light process that works pretty well for now. However this isn’t great when we have to rely on users to let us know about bugs! This is why we use Bugsnag that let us know of any 500 or JS error in our live environments:
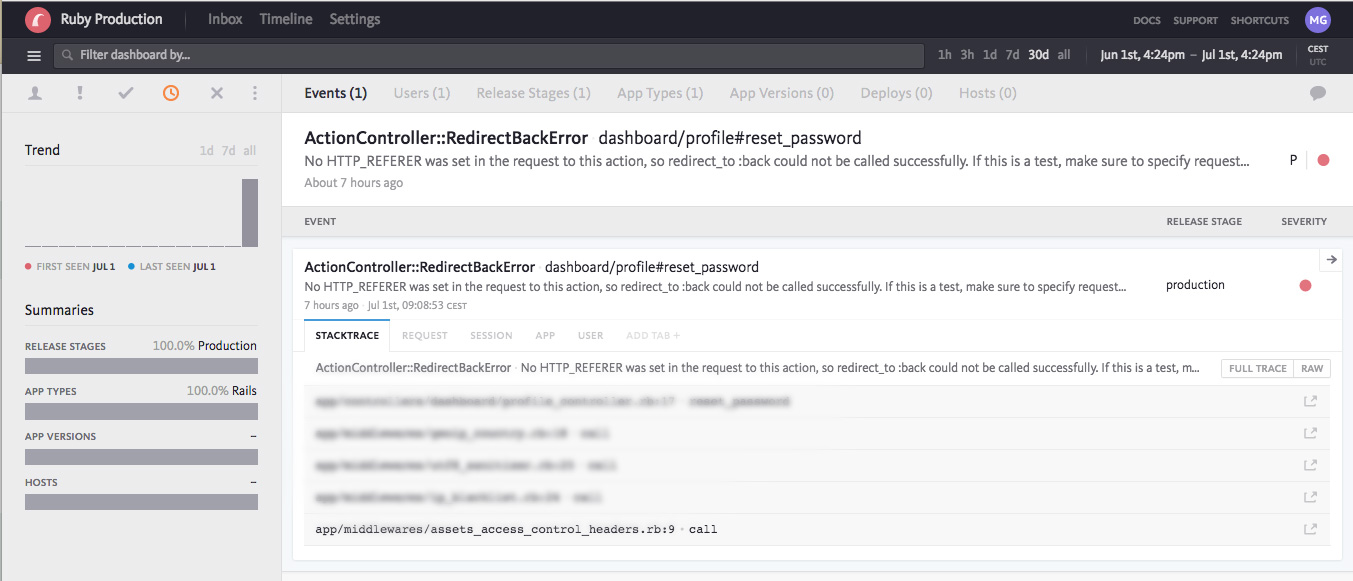
In the examples above the error is pretty straightforward: someone tried to do something and it failed. However the most worrying bugs are the one that are failing silently. They are harder to detect and can cause a lot of problems. For instance if you have an issue with Facebook connect that fails 10% of the time silently, you will not see any 500 error… however you will see a decrease in KPIs related to the Facebook connect feature.
This is why we use business metrics to detect possible issues as it’s a great way to detect possible regressions. We use a wide variety of tools, depending on the situation, from Universal Analytics to Redash. This gives us a simple way to detect changes in patterns and react accordingly.
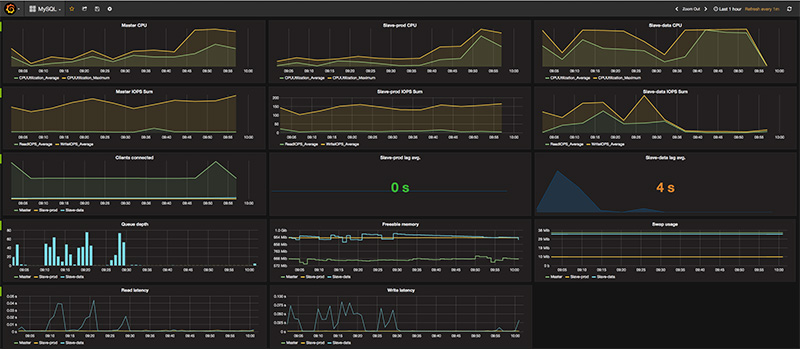
For performances and other technical monitoring, we use New Relic and Logmatic. We also have a setup with Telegraf, Influxdb and Grafana to check our time based metrics:
We have a lot of others solution to be completely sure that everything works properly. For instance we will write “checker jobs”, which is basically a cron running frequently and checking if data is shaped as expected.
We use various tools with specific escalation policies in order to react quickly to any issues. For instance PagerDuty will phone us if some metrics are getting bad, but we also built a Slack bot that let us know of less critical issues:

To make sure that every problem is taken care of, we have set up a new role we call the “Bugmaster” who is in charge of checking all issues.
We work hard on reducing the cost of releasing to production. If you can ship quickly and safely, you’re able to remove any bug quickly. To do so we constantly work our internal processes and tools. For instance we have a command line interface connected to Slack that allows us to release a new version of the website:

Once a fix has been made, it’s important to have new automated tests to prevent regressions.
Detecting and fixing bugs is not the most fun part of the job… and it’s way better to have none! This is why we invest a lot in a solid test suite that runs on CircleCI, an efficient Git workflow. We also focus on shipping small things quickly using feature flags instead of a doing massive releases and, of course, we have a great team of individual that want to ship working software.
Our workflow and tools changed a lot over the years, but it’s getting more and more robust. I can honestly say that it is very rare when we’re caught off guard by a serious bug, which is great for our users.
Overall it feels great to be working on a project that is evolving quickly, but can keep a good level of quality.
This is a simplified update of an article originally posted on my personal website. You can read the previous version here.