Getaround connects safe, convenient and affordable cars with people who need them to live and work. We aim to create the world’s best carsharing marketplace that make sharing vehicles superior to owning them. Our community includes people who rely on our cars for on-demand mobility, and owners who share cars on our platform, including those who operate their own carsharing businesses.
Our vision is to make our cities and communities better places to live by:
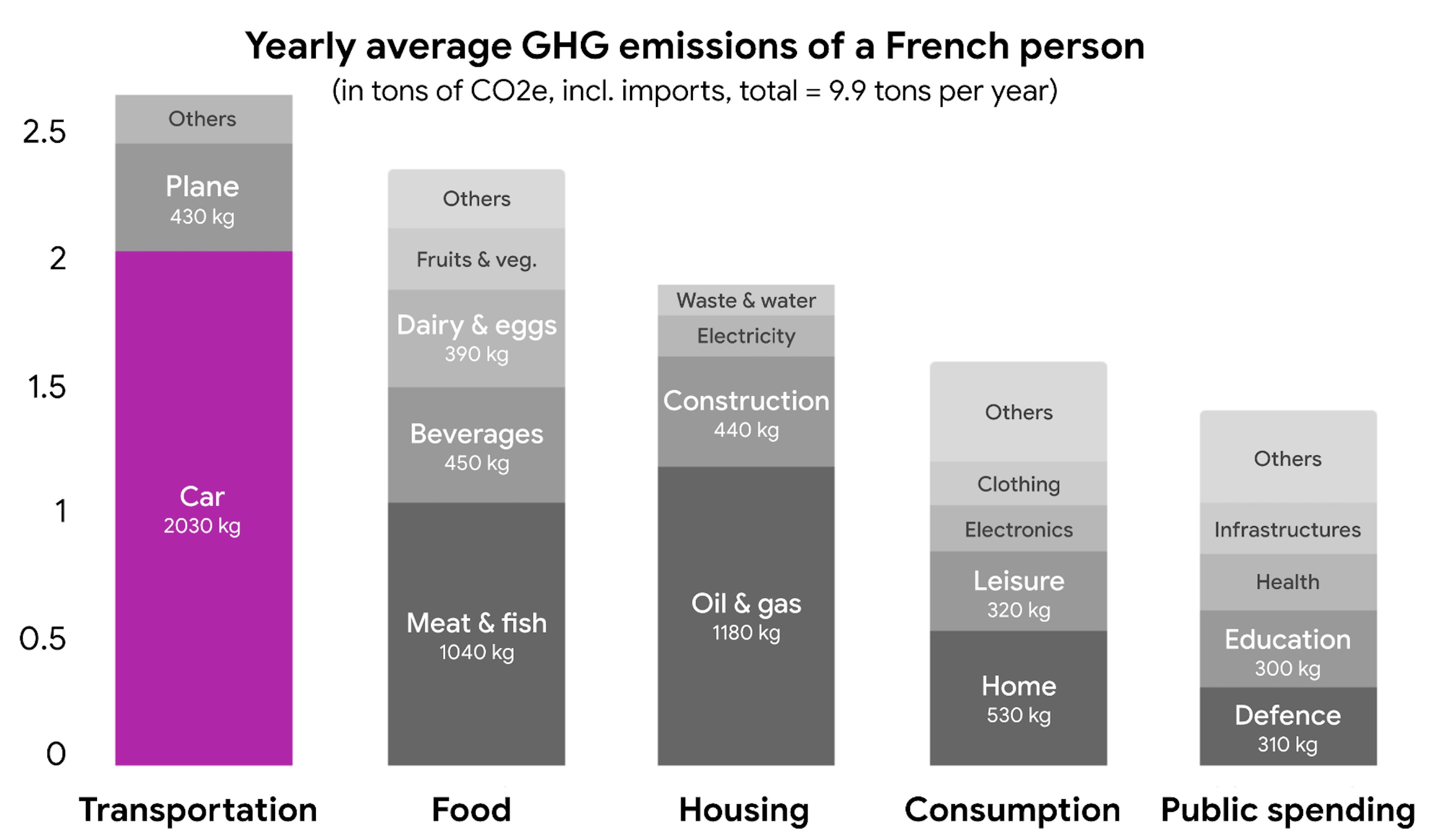
As a reminder the biggest carbon emitter in most countries are the cars, and this is what we have an impact on at Getaround.
Our team is collaborative, positive, curious, and engaged. We think fast, work smart, laugh often, and are looking for like-minded people to join us in our mission to disrupt car ownership and make cities better.
It’s an exciting time to be building the website, APIs and native applications that facilitate this revolution. On this blog, members of the Getaround engineering team share tips, insights and lessons learned during this experience.
Every quarter, the team members from our offices all around Europe gather in Paris for a big all hands presentation and party.

Getaround (“Drivy” back then) was historically in PHP. Then in 2013, we migrated to Ruby on Rails and we’ve never looked back. We’re currently running Rails 5.2, as well as our native iOS and Android apps. Overall, we value solid quality code, supported with a lot of specs, that can be shipped to production multiple times a day.
We use Rspec, Capybara and Jest, and integrate our code into CircleCI. We also monitor the production environment closely with dashboards built using New Relic, Telegraf, InfluxDB and Grafana, just to make sure everything is ticking over nicely. We use New Relic and Fluentd to parse and analyze our logs, and we check Bugsnag & Sentry to see if any 500 errors are causing issues for our users.
We work according to our design system, so that we don’t have to redesign forms and buttons every week. We use Typescript and have a growing set of React components for JS-heavy parts of the application. We also use Webpack instead of the classic Rails asset pipeline, and Yarn to manage dependencies.
On the mobile side, we use Kotlin and Swift.
As far as data is concerned, we use MySQL on RDS with multiple replicas and a dozen Redis instances to store things. We also pull data from multiple sources, then clean them and transform them with dbt before they end up in Snowflake, our data warehouse. We create, schedule and run data pipelines with Apache Airflow, where tasks are written in Python and executed in Fargate. And then we make sense of all this data using Redash and Tableau for our dashboarding needs.
We don’t over engineer our processes: we have a growing internal wiki, keep our tools simple, like our homemade automated release tool that is connected to Slack to remove headaches, avoid bugs in production and move fast. But we’re also not afraid to challenge these processes regularly, and make additions in order to keep improving things.
{kind=link}
{kind=link}
{kind=link}